Sentiment Analysis For Reputation Management
A look at the possibilities of traditional AI techniques for managing your media reputation.
This is the second post in a series of posts discussing AI techniques for reputation management. Find the previous post in this series here.
In this post we will look at sentiment analysis, a very common AI technique that can help your organization identify online mentions of your brand that you want to react to. Sentiment analysis is very useful in a media monitoring context because even with automatic detection of your brand mentions, it is still challenging to identify mentions that require your attention when your brand generates thousands of mentions daily.
We’ll start with a brief description of what sentiment analysis is, followed by an explanation of modern AI techniques for sentiment analysis.
What is Sentiment Analysis?
Sentiment analysis is a collection of techniques for automatically detecting subjective opinions and feelings expressed by some source towards some target in natural language. Online product and service reviews is a good example of a domain where sentiment analysis can be made useful, since the source and the target are easily identified as the author and the subject of the review respectively.
Take for example the following review of the Hypefactors app taken from the review site capterra.com:
Really easy interface and configuration. The customer service team is very helpful and the set-up was done in one day.
The subjective opinion expressed by the author towards Hypefactors is positive in this case, as indicated by phrases such as easy interface and configuration and helpful customer service team.
Sentiment analysis is a challenging problem. Simple rule based systems often fail because of the huge variability of natural language. Consider for example the simple sentence
The movie is surprising with plenty of unsettling plot twists.
A successful sentiment analysis system must understand that the normally negative word unsettling is actually positive in the context of movie reviews. Add to this the complexities of negation (I don’t hate that movie) and sarcasm, and its clear to see that coming up with a list of rules that determines the sentiment of a phrase is close to impossible.
For this reason most modern systems is based on a statistical approach that attempts to learn what positive, negative or neutral sentiment means. These techniques are collectively known as machine learning.
Machine Learning techniques for Sentiment Analysis
Using a large collection of reviews and associated sentiment labels, it’s possible to train a machine learning system to recognize such linguistic indicators of sentiment, and use them to accurately predict whether the sentiment of any review is negative, neutral or positive. Most modern sentiment analysis systems are based on a machine learning technique called supervised learning. In this learning paradigm, the system is produced by a process referred to as training in which a training algorithm is applied to a large collection of inputs (text in this case) and desired associated outputs. The output of training is a model. The process is illustrated below.
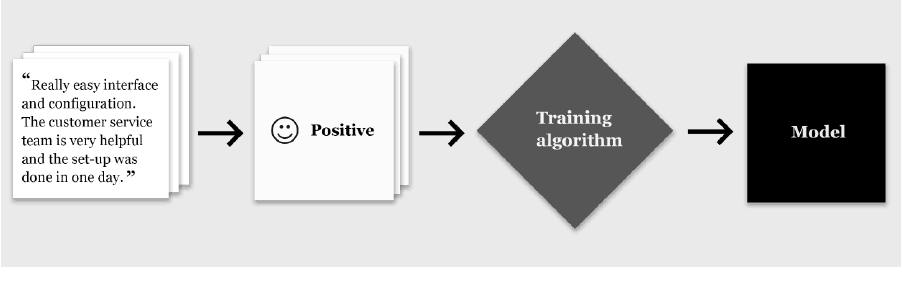
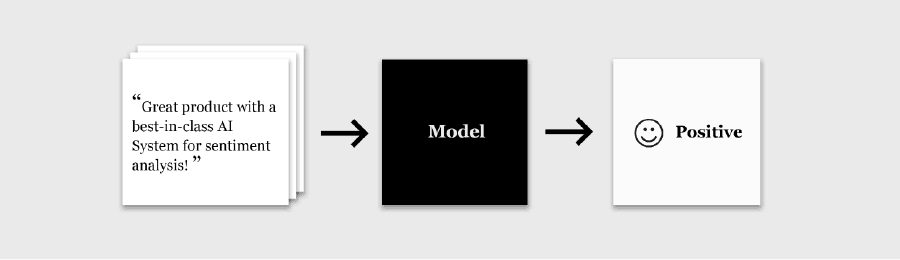
The model is a mapping from text to its most likely label. Once the model is trained it can be used to classify new, unlabeled data without human input.
Today, deep learning models are by far the most common models used in supervised learning for natural language processing problems such as sentiment analysis. Deep learning is an umbrella term that covers a number of different techniques with the common trait that the model consists of a series of nonlinear vector-to-vector transformations of the input, until the output of the final vector transformation is used as input to a classification algorithm.
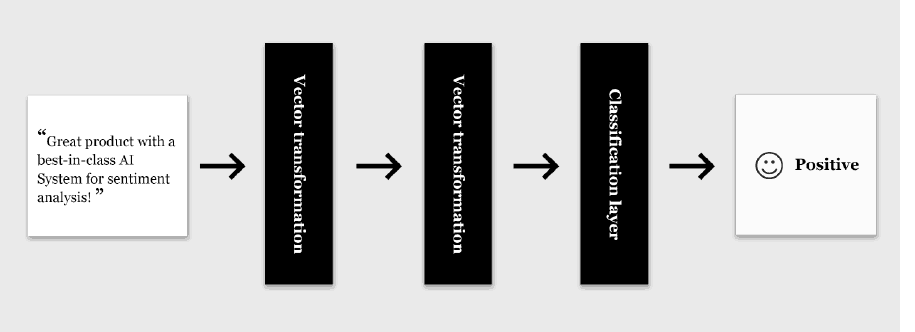
The training algorithm for deep learning models is called backpropagation. It works by adjusting relevant parameters of the model’s vector transformation layers and classification layer in a direction that improves the accuracy of the model on the labeled input data. In other words, the model learns to recognize patterns in the training data that are evidence of negative, neutral or positive sentiment.
In this post we have looked at sentiment analysis as a tool for reputation management. We have seen how sentiment analysis can in some cases alert you to mentions that carry negative or positive sentiment. We have also discussed why building a sentiment analysis system pose many challenges because of the variability of natural language.
Conclusion
In the next post in the series, we will discuss how Hypefactors is improving the state-of-the-art in sentiment analysis, by addressing the shortcomings of sentiment analysis of reputation management.